
How to never hit limits on Claude Code?
Using open weight free models via OpenRouter

I am redesigning my website. My last update goes back more than 3 years. This was still the pre-AI era, where I had to read up a lot of documentation, scour through GitHub to find inspiration (and reusable code) and spend hours on Stack Overflow, debugging plumbing and syntax issues.
But now we have Claude Code, which does most of these tasks for me in the terminal.
I am on the $20 Pro plan. And the limits on it are not reasonable enough to work on any serious long-form project.
I also pay $20 for Gemini and couple that with other SaaS subscriptions, my monthly software bills easily touch ~$80-$100.
When I asked my wife for permission to spend $200 on a Claude Max plan, I received a vehement veto.
It was down to me to figure out a workaround. And I decided to break things down from first principles.
What is Claude Code?
It is an agentic coding tool with two distinct components (they’re easy to conflate):
The harness. The local program that runs in your terminal. It reads files, edits them, executes shell commands, manages git, asks for permissions, holds conversation state, injects memory files like CLAUDE.md, and runs the loop: think → call tool → observe result → think again.
The brain. The LLM is the harness that calls out to whenever it needs to reason. The brain produces no side effects on its own. It reads a prompt and emits text, including tool calls. The harness is what actually executes those tool calls on your machine.
The harness is the durable surface. The brain is, in principle, a commodity slot. Conceptually, swapping one model for another within the same harness should work.
I researched and figured that Claude, in fact, offers users a way to slot other models in by setting environment variables.
Consequently, there are two options to swap the model:
Run an open weight/offline model like Google Gemma locally (via services like Ollama)
Leverage APIs for replacing Claude with models from other labs
The problem with 1 is that I have a Mac with M2 and 8 GB RAM, which is not capable enough to run any decently powerful model. So it was ruled out.
Option 2 had its own problem. Plenty of models exist, but integrating different APIs is overhead, and per-token API costs add up fast on agentic workloads where every turn re-sends the whole context.
Thankfully, OpenRouter exists, and I was able to come up with an elegant solution.
OpenRouter is a unified API and marketplace that lets developers access hundreds of AI models, from proprietary ones like GPT and Claude, and open-weight ones like Llama, Gemma, and Qwen, through a single standardised interface. It sits in front of every major model and forwards your requests to whoever is hosting it.
You give OpenRouter money, OpenRouter gives the host money, the host runs the model and sends tokens back. One API key, one billing system, one endpoint, and switching models becomes a configuration change.
I hooked it to the Gemma 31-billion parameter model and was able to get 60-80% of the performance that I get from Claude Opus 4.7—far more than I expected from a free open-weight model running through a third-party router.
There are several other free models to choose from. And the OpenRouter website provides a comprehensive analysis of features to make the decision easy.
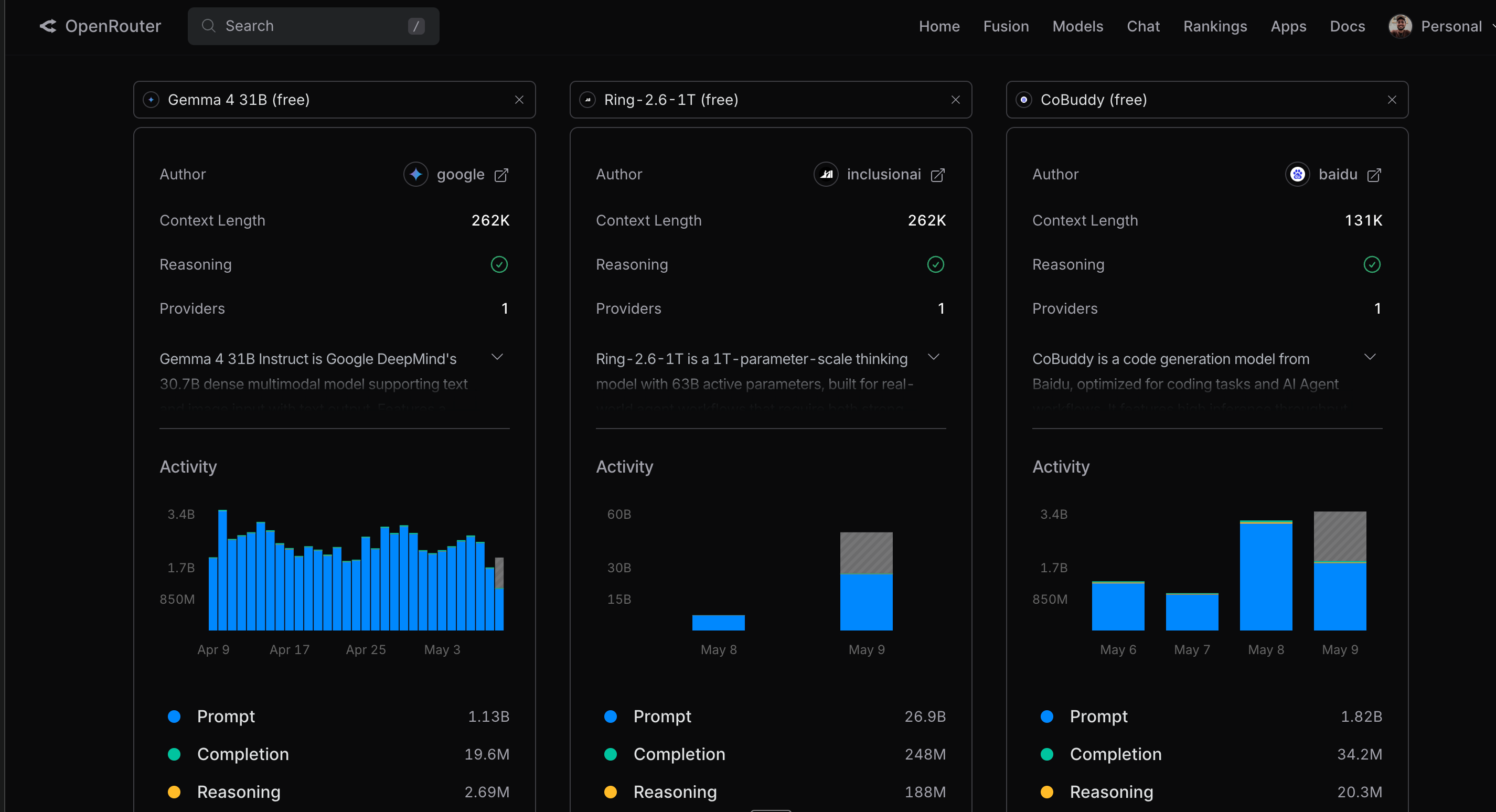
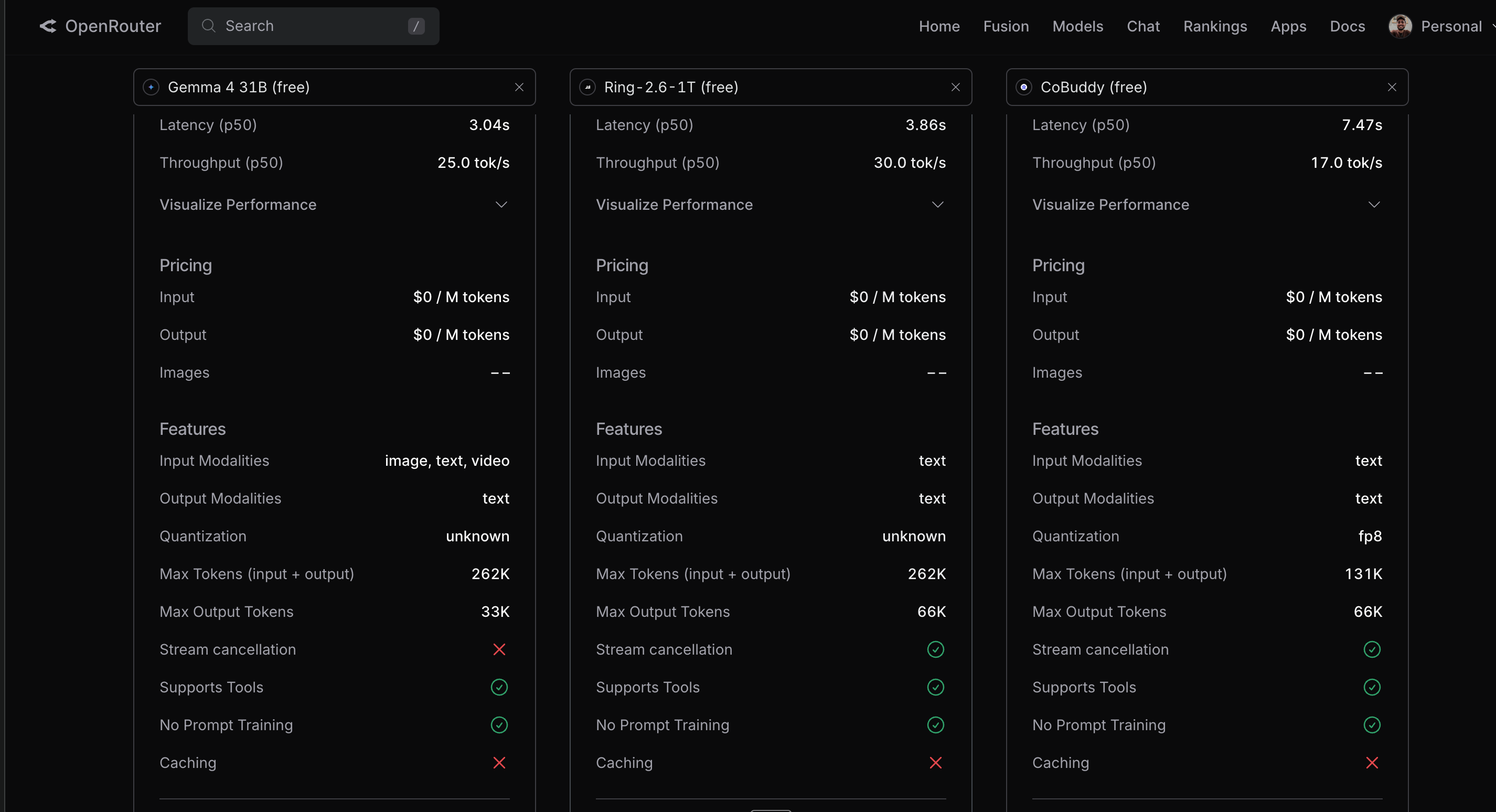
Here is how you can set it up.
Run nano ~/.zshrc in the terminal and paste the following at the end of the profile.
export OPENROUTER_API_KEY="<your-openrouter-api-key>"
export ANTHROPIC_BASE_URL="https://openrouter.ai/api"
export ANTHROPIC_AUTH_TOKEN="$OPENROUTER_API_KEY"
export ANTHROPIC_API_KEY="" # important — must be explicitly empty
Two lines do the real work—ANTHROPIC_BASE_URL redirects calls, and the empty ANTHROPIC_API_KEY stops Claude Code from quietly falling back to your real Anthropic key.
Restart the terminal and open Claude Code in the working folder.
For free Gemma, run /model google/gemma-4-31b-it:free.
The full guide is on OpenRouter’s docs.
Two callouts:
Adding a Google AI Studio API key will ensure that there is no throttling
The above-mentioned code snippet will have to be removed to run Claude Code with the standard Anthropic models
Here is what happens when I send a request:
Terminal → Claude Code (the harness). Claude Code assembles the prompt—my message, the relevant
CLAUDE.md, recent conversation, file contents it has read, tool definitions, and any pending tool results.Claude Code → OpenRouter. Because the base URL is overridden, the harness sends that prompt to
openrouter.ai/apiinstead ofapi.anthropic.com.OpenRouter → an upstream provider hosting Gemma. OpenRouter is a router and billing layer; it doesn’t run the model itself. It picks an upstream provider like Together AI, DeepInfra, Groq, Nebius, Chutes that hosts a copy of Gemma’s weights, and forwards the request.
Provider GPU → tokens back. The actual matrix multiplications happen on someone else’s GPU, in some data centre.
Response back through OpenRouter → Claude Code → terminal. The harness parses the response, executes any tool calls, feeds the results back into another model call if needed, and eventually replies.
The harness is the part you’ll keep using. The brain is something you can choose. Right now, I bounce between Claude when I have the budget and Gemma when I don’t, and the workflow doesn’t change. It is liberating not to have to sit and wait as the limit resets.