
Why Google might win? (4/5)
On the model

So far in this series, I have argued that Google has three underlying moats.
Custom TPUs give it a cost edge on every token it serves.
Private infrastructure that was built to run Search and YouTube eliminates the margin leakage every other lab pays.
Proprietary data–complete, multimodal, and compounding as the public internet runs dry–is the layer that capital alone cannot replicate.
None of this matters without a frontier model on top. Thankfully, Google has one.
But in early 2023, that was not obvious. ChatGPT had reached 100 million users within two months of launch, Google had declared code red internally, and its first response, “Bard”, gave an erroneous answer in its launch demo and wiped $100 billion in market cap in a single day.
In April 2023, Sundar Pichai, acting like a wartime CEO, took a bold step. He merged1 Google Brain and Google DeepMind–the two AI research labs within the company.
Google Brain was the applied research arm: obsessed with getting AI into products, optimising for what could be trained, deployed, and scaled across Search, Ads, and Translate. Its theory of intelligence was statistical: expose a model to enough data, and useful patterns emerge. Scale is the mechanism. The Transformer paper that every major model is built on came out of Brain.
Google DeepMind was solving a different problem: artificial general intelligence, a system that could reason through problems it had never seen. Its method was reinforcement learning: define a precise feedback signal, then train the model to maximise it. Think of it like learning a video game by trial and error. You try something, see whether the score went up, adjust, try again (except across millions of attempts).
Over the course of the past two years, this collaboration, combined with the discussed structural moats, has led to Gemini having distinctive characteristics.
Gemini architectures allow the processing of up to 1-2 million tokens in the context window (among the highest in commercial models).
Gemini serving costs have fallen 78% year-over-year, and API pricing runs 5-10x cheaper than OpenAI’s comparable models.
Gemini is natively multimodal (a single neural network trained on text, images, video, and audio together from the start). When competing models process an image, a separate encoder translates pixels into a representation the text model can read (like handing a language-only brain a written description of a photograph). In practice, this gives Gemini an edge in tasks that require reasoning across modalities simultaneously–analysing a video’s visual content alongside its audio, or interpreting a chart embedded in a document in relation to surrounding text.
Consequently, it is imperative to analyse what this translates to on the inference layer–in terms of utility and applications. To evaluate the models holistically, I believe three parameters matter:
The first is whether people prefer using it.
On Arena (formerly LMArena), where real users vote on two anonymous models across whatever tasks they actually care about, Gemini has two models in the top five in the Text Arena. More than any other company. Claude leads the leaderboard; Gemini trails narrowly.
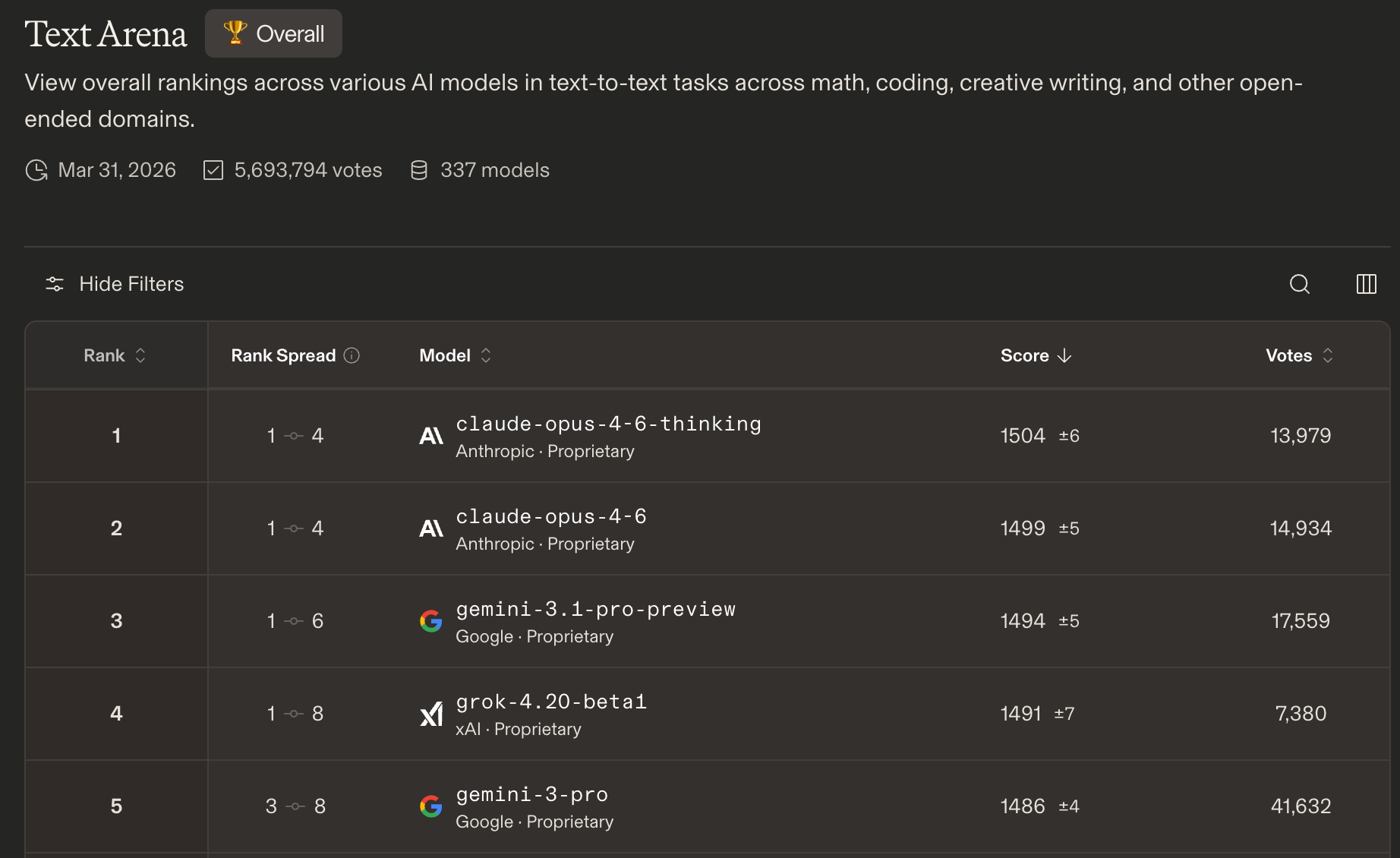
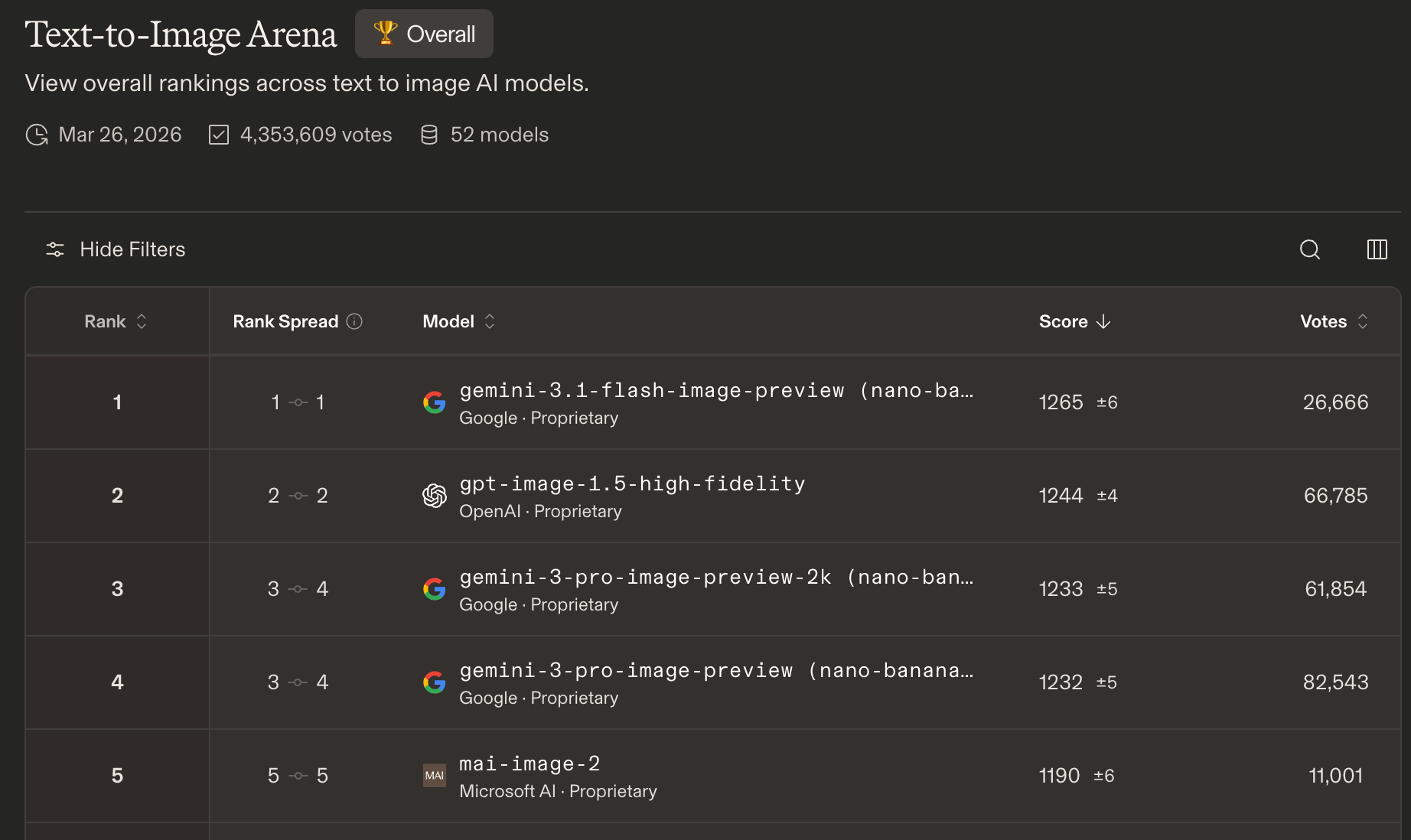
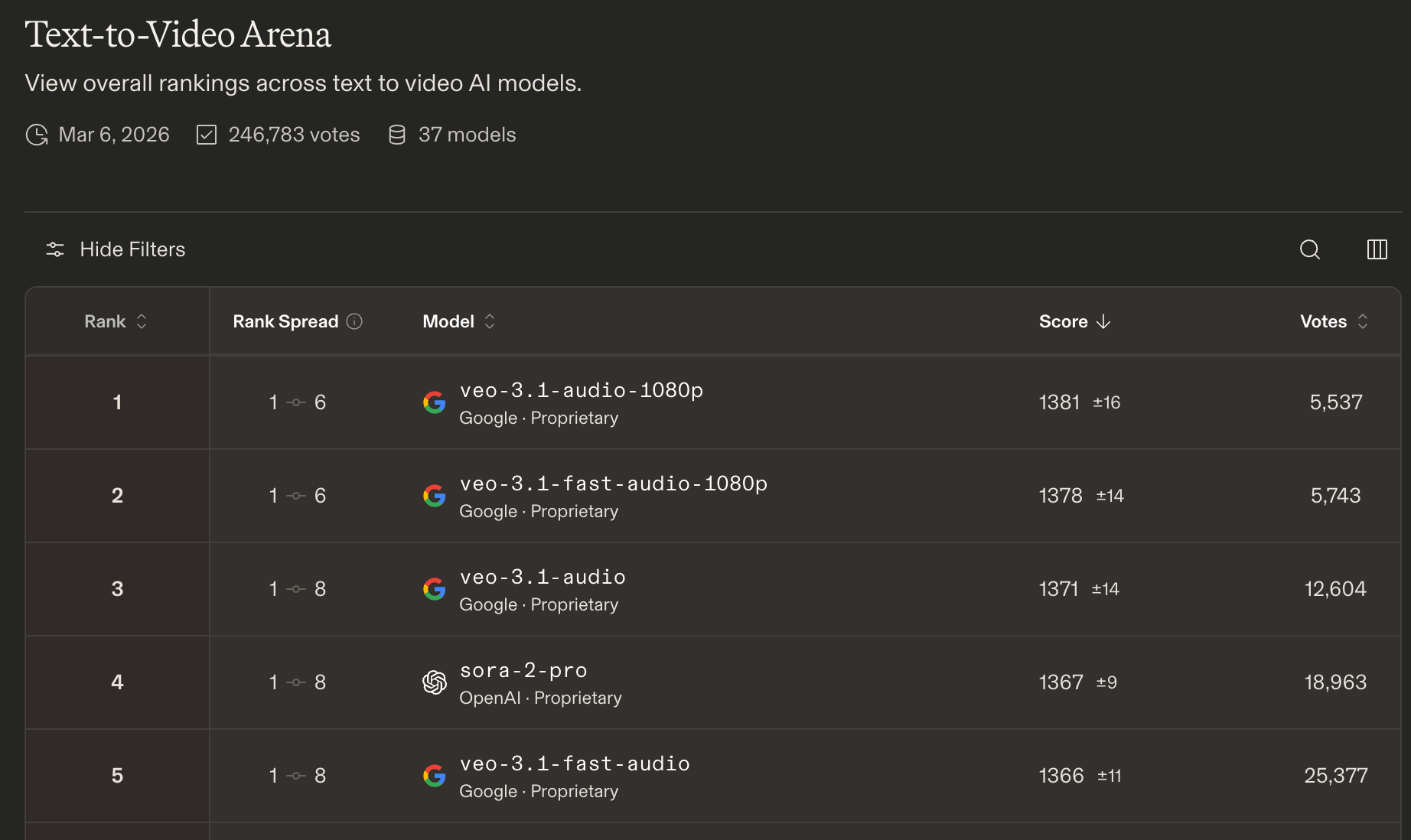
On Text-to-Image and Text-to-Video Arena, Google is dominant with Gemini and Veo taking most of the positions.
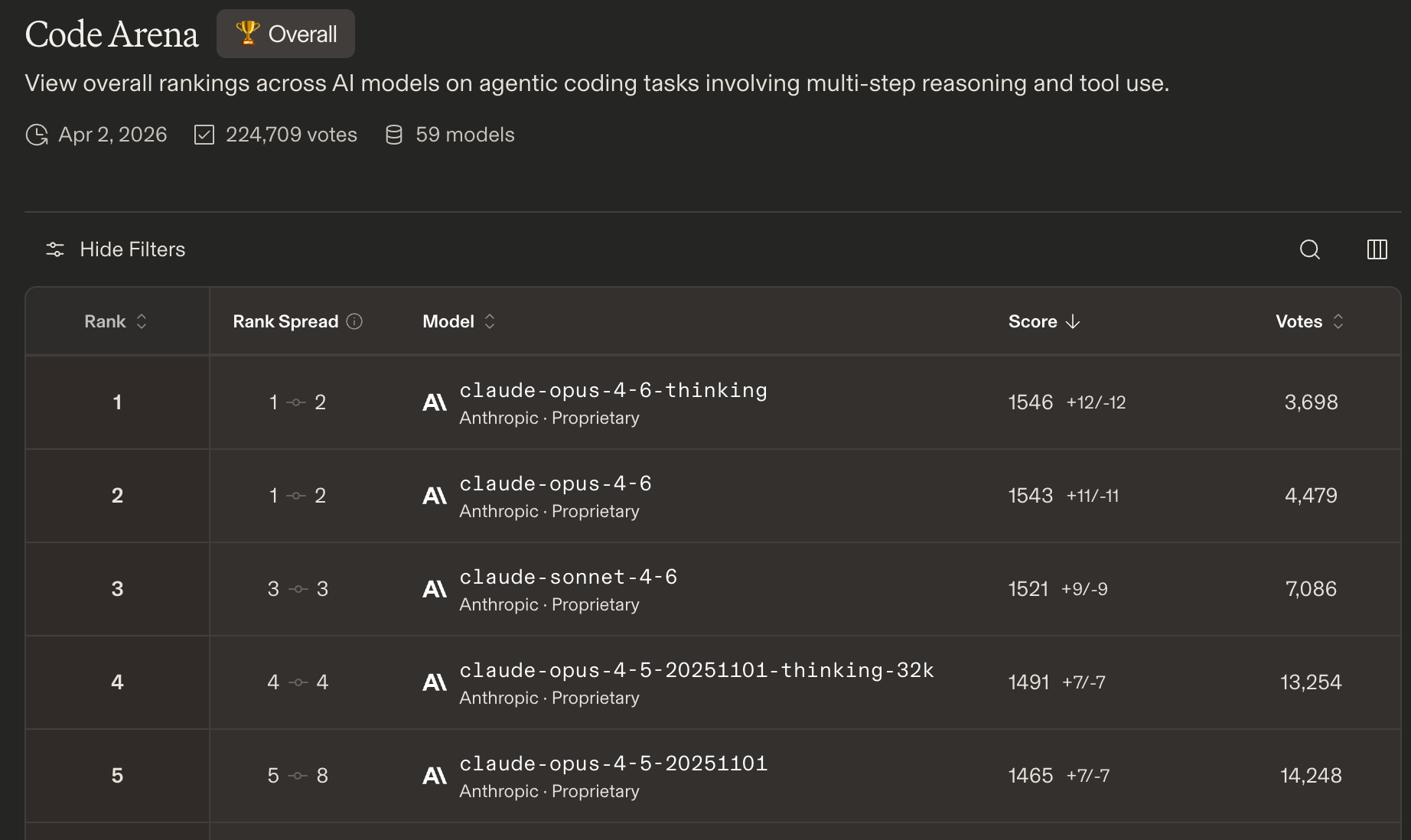
However, in the Code Arena, Claude is the undisputed king with Gemini coming in at seventh.
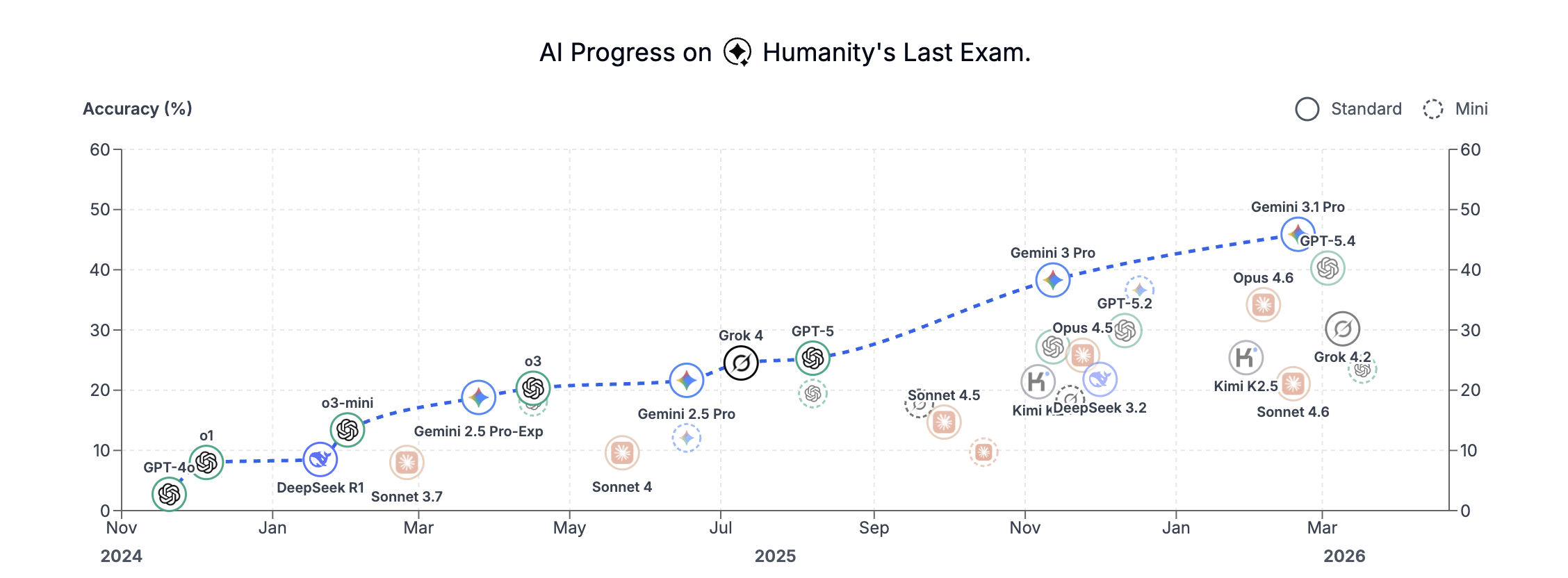
The second is performance on the hardest problems with canonical right answers–competition mathematics, formal science, and competitive programming. Gemini Deep Think holds gold-medal level across multiple Olympiads. On Humanity’s Last Exam2, which tests frontier expert knowledge across all domains, it holds the highest published score.
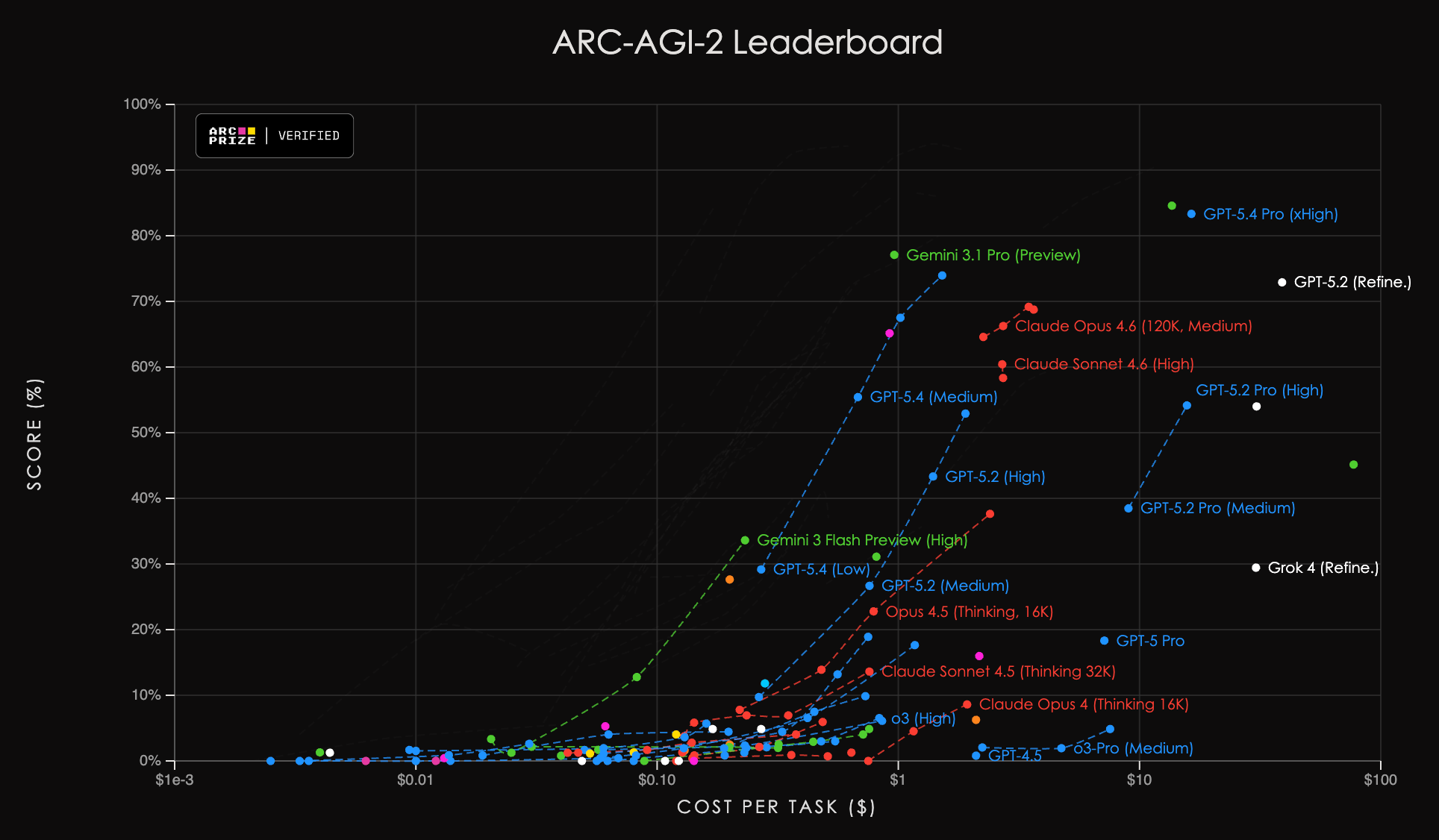
The third is genuinely novel reasoning, measured by ARC-AGI-2. This benchmark was specifically designed to be immune to the normal tricks–it cannot be gamed by training on similar problems, because the problems are genuinely novel visual reasoning puzzles that have never appeared in any training corpus. At launch in early 2025, every major model scored near zero. Chain-of-thought reasoning, extended compute, and even brute force failed to make a mark. The benchmark was designed such that it could not be gamified.
Gemini Deep Think, however, scored 84.6%, verified independently. Gemini 3.1 Pro scored 77.1%. Going from near zero to above 80% was made possible through a reinforcement learning-based reasoning approach, applied to a problem class that scaling-only approaches cannot crack.
These artefacts prove that Google has been able to achieve best in class outcomes with Gemini. To be able to do that within two years of the Bard fiasco is a truly commendable feat.
These performances are not set in stone. And as is evident from the leaderboards above, other frontier labs are not far behind. Talent is fungible, techniques are being replicated, and access to capital is also democratised to a large extent. Hence, the only thing that matters at this layer is sustained competitiveness. Combining it with the other structural advantages and distribution (which will be discussed next), Google can ensure dominance in the time to come.
Under its 2014 acquisition terms, DeepMind was guaranteed operational autonomy and an independent ethics board, allowing the London-based lab to operate in a silo that actively resisted integration with Google Brain until the competitive threat of OpenAI forced their 2023 merger.
Humanity’s Last Exam, a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. The dataset consists of 2,500 challenging questions across over a hundred subjects. They publicly release these questions, while maintaining a private test set of held out questions to assess model overfitting.